此為《GPT-4V 微軟評測報告 》第九章實測下篇
本文是 GPT-4V 微軟評測報告 第九章的第二篇分享,我們深入探討了可用於影像管理與影像生成的眾多應用場景。例如,GPT-4V可以應用於相簿管理,為照片自動整理提供個性化描述的創新解決方案。此外,它還能助您評估圖片生成的適切性,宛如一位圖像轉換顧問,逐步指導您提升與影像轉換模型(如instruct pix2pix)間的溝通效率。
對於那些從事影像處理工作的專業人士來說,這些應用絕對值得您深入瞭解。
另外,如果您喜歡我們這樣的內容,很歡迎到這裏訂閱我們的電子報,我們接下來的內容會在這裏優先發佈: ChatGPT 落地研究 | Ted (substack.com)
這部分是我特別鍾愛的一個應用場景,因為它貼近日常生活。想像一下,當你提供了 ChatGPT 你家人的頭像以及他們的暱稱,它就能夠幫助描述我們相簿中每張照片的細節。
此外,
當我們從珍藏的照片中選出某些想要特別標記和描述的人或事,ChatGPT能結合當時的場景和外貌特徵,仔細地進行個性化描述。這無疑是整理相簿的一種極佳方式!
報告中關於照片管理的部分,是透過實際的人物照片進行實驗。我們則是以一個童話故事的圖片進行了模擬。這樣的方法也同樣適用於整理我們自己的生活照片和親友的照片。讓我們直接看一個範例。
由於ChatGPT目前一次最多能處理4張照片,而我們的人物設定稍嫌繁多,因此我們首先向它提供人物設定的資訊: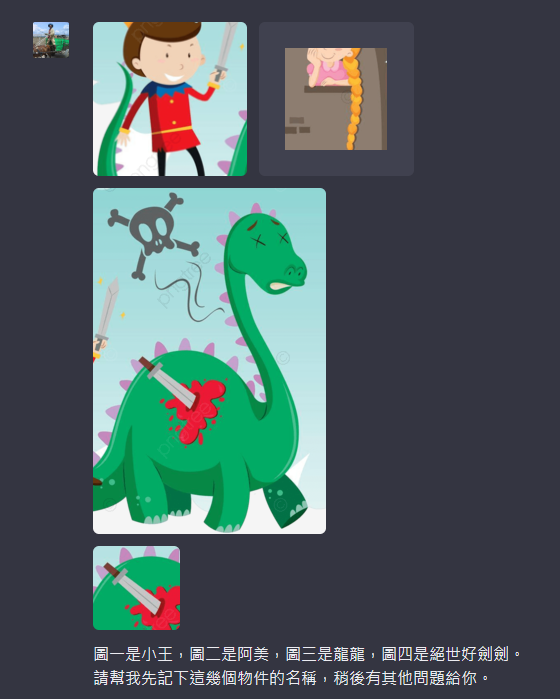
ChatGPT很順利地記住了這些人物: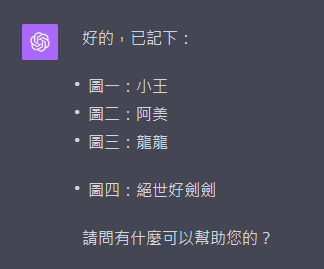
我們接下來實驗看看它是不是真記得這些人物: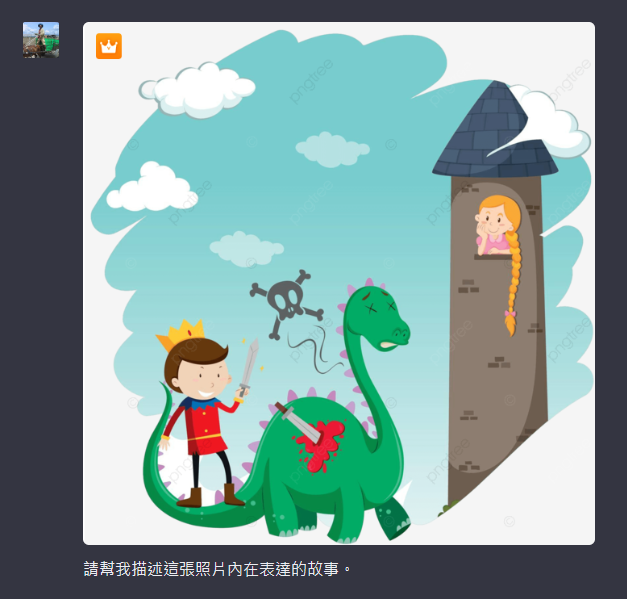
ChatGPT的反應:
哈哈,真的很歡樂的測試,雖然它編的故事中,難免還是還是有一些小毛病,例如它說【穿著皇冠】,動詞使用穿是蠻明顯的錯誤,還有骷顱頭的標誌,我們的認知是代表龍龍掛掉了,但是它有著不太一樣的詮釋,不過我們可以看出ChatGPT確實能夠辨識我們所標記的人物,並能夠根據照片中的情景生動地進行描述。每當讀到它描述某人「手中持有絕世好劍劍」這句話時,就令人覺得好笑呀。
GPT-4V的能力不僅限於將我們標記的物件賦予名稱,從而描述整個場景,它還能做到相反的操作:在我們標記了特定物件後,它能結合整體畫面的情境,進行詳細的描述。
這到底是怎樣的一個過程?讓我們通過一個具體的例子來更直觀地理解上述描述。這裡有一張《動物方城市》的海報,我們專門挑選了其中的三個角色進行標記,然後請求 ChatGPT 依據整體畫面,對這些特定的人物進行重點描述。讓我們看一下提問的具體方式: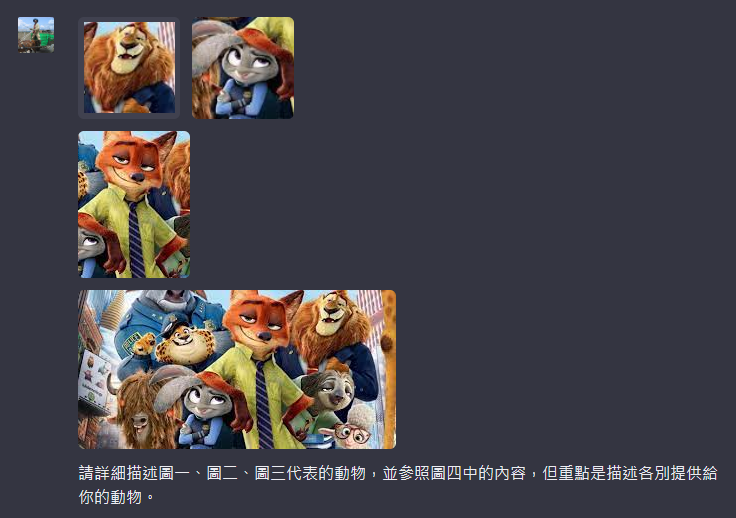
現在,讓我們來看看ChatGPT的回答。ChatGPT 不僅對他們的外貌進行了細致的描述,還根據整體場景進行了額外的詮釋。這樣的綜合描述能力,的確非常讓人驚嘆。
在當今的影像生成領域,我們可以看到各種應用,如從文字到影像的轉換模型(例如 OpenAI 的 DALL·E,以及 Stable Diffusion 等),還有從影像轉換到影像的模型,比如 pix2pix。這些模型的初步操作和最終產出的質量評估,很大程度上取決於提示詞與目標影像之間的匹配程度。幸運的是,GPT-4V 也提供了這類評估功能。它甚至能結合自身的語言模型和影像分析能力,幫助我們逐步優化我們的影像生成提示詞。下面,我們就來透過一些範例,細看其細節。
相似度評分究竟是什麼呢?當我們對同一張照片提供不同的描述時,讓我們看看 GPT-4V 如何反應。首先,我們嘗試提供一個精準且直接的描述,基於照片內容所觀察到的事實。
那麼,如果我們的描述稍微與圖像所呈現的事實有些出入會怎樣呢?
舉例來說,我們故意描繪一個貓咪盯著鍋子流著口水的情景,這實際上是一個基於想象的描述。由於這與實際影像內容不符,評分自然會相對較低。
探索上述概念的另一層次,當影像中融合了文字元素,情況又會如何呢?讓我們來看看: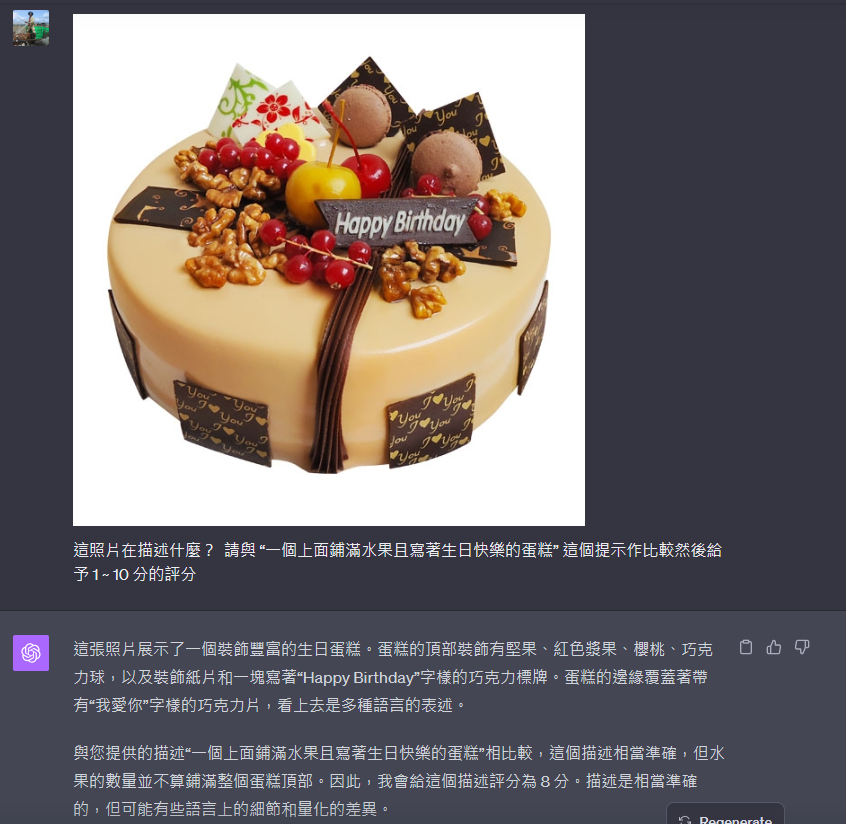
照片內描述的文字,我們故意使用中文意思,的確整個的評估還蠻聰明的,我們物品的描述出入不會太大,文字也用類似的語義但是不同的文字表達,結果 GPT-4V 腦袋轉得過來,整體給了我們 8 分的高分。
如果進一步精緻化我們的描述,結果又會如何呢?讓我們看看下一步的測試: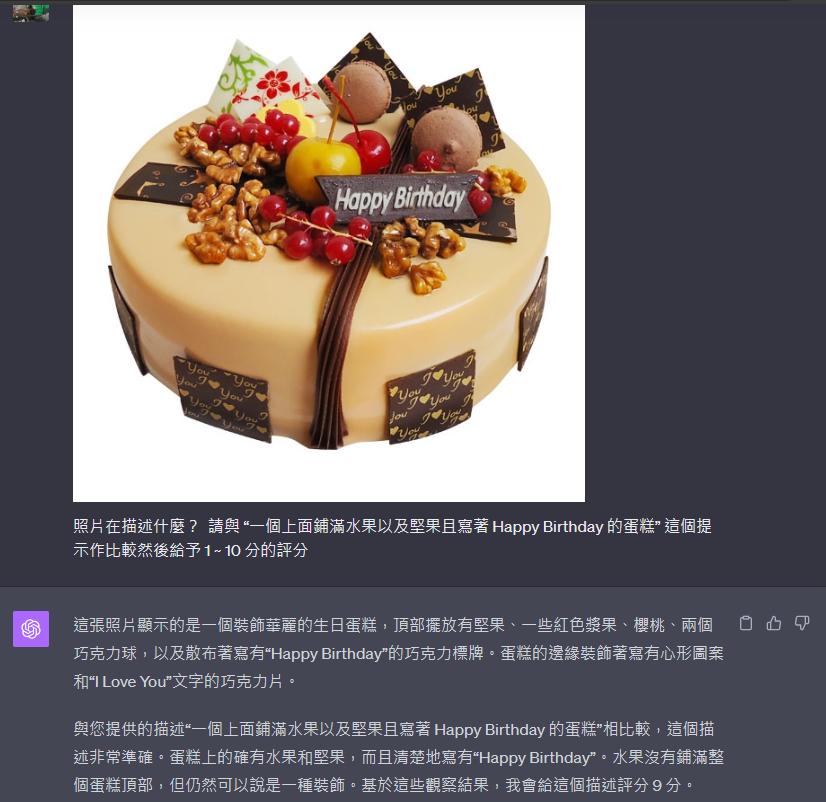
結果是 9 分,確實,相較於我們之前的嘗試,這次的描述更為精準,而且在文字部分也保持了原文的表述。因此,8 分和 9 分的微妙差異讓我們能夠明顯看出兩種描述的優劣。
GPT-4V 在影像領域的另一項應用與 instruct pix2pix ——一種影像編輯模型的聯手協作有關。簡而言之,此影像編輯模型允許我們利用自然語言指令來對附加的圖片進行細微的編輯或轉換。以下我們提供原始論文中的示範圖片,讓大家更直觀地理解上述介紹:在中間上方的圖中,左側是原始圖片,而右側則是我們使用“天空加上煙火”這個提示詞後,模型自動生成的新圖片。
簡介過 instruct pix2pix 後,我們來探討 GPT-4V 如何與它協作,逐步精煉我們圖片生成的提示詞。
首先,我們有一張原始照片,目標是利用 instruct pix2pix 將其轉化為水彩畫風格:
我們嘗試了一個簡單的指令:“將其變成水彩畫(make it a watercolor painting)”。instruct pix2pix 生成了以下圖片:
可能您會覺得這張圖片看上去有些許像水彩畫,但品質尚未達標,對吧?沒問題,我們可以讓 GPT-4V 幫助我們改善提示詞。這是我們與 GPT-4V 的對話記錄: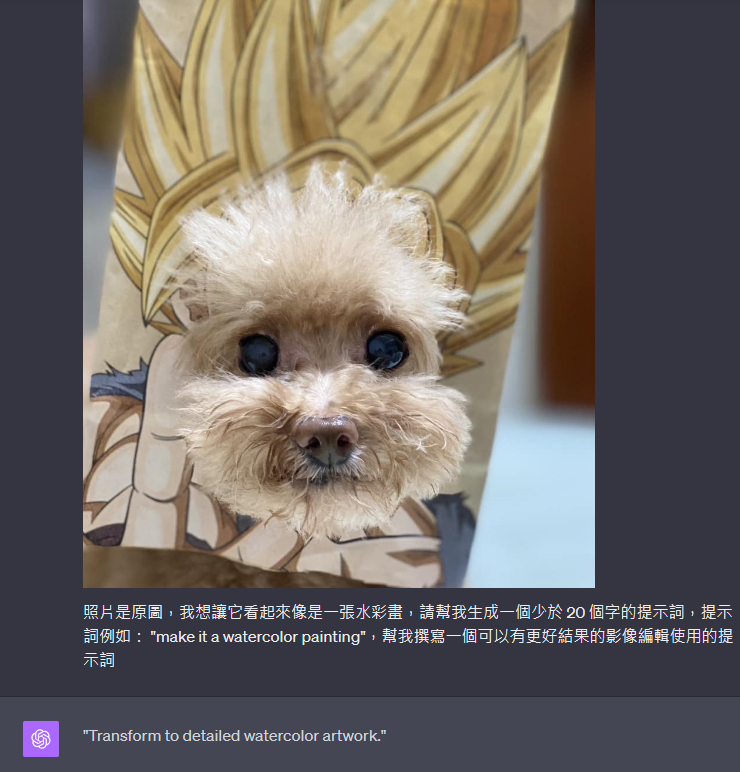
隨後,我們按照它推薦的“Transform to detailed watercolor artwork”再次嘗試,來觀察instruct pix2pix所呈現的效果:
在我看來,這次的結果似乎更接近水彩畫的質感了,雖然仍然有改進的空間。因此,我們不妨再次諮詢GPT-4V,詢問的方式如下:
這次GPT-4V給予了新的指令“Enhance to vibrant, precise watercolor art。”,我們迫不及待地想看到效果如何:
嗯…結果出人意料,不知怎麼評論,但我們不放棄,決定再給GPT-4V更多的建議和反饋,希望進一步改善結果: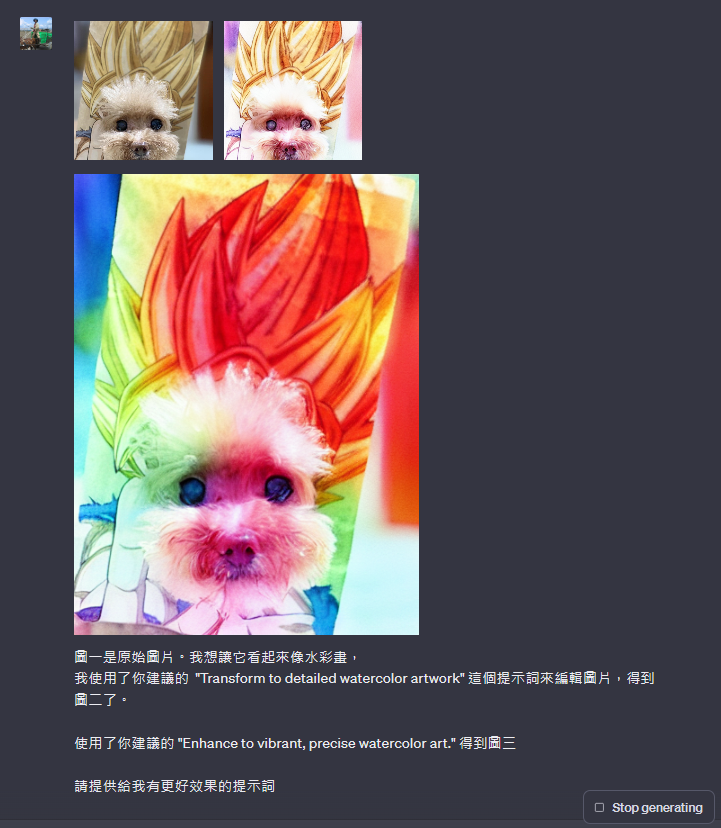
下面是它實際的回覆:
最終,我們使用了“Apply artistic watercolor effect with enhanced depth and dynamic shading”作為指令,期待instruct pix2pix能夠給予我們更滿意的成果:
似乎經過不斷的嘗試與調整,質感確實有所提升,至少最後這幅畫,與之前相比,水彩的質感更佳,小狗的臉部顏色也不再那麼雜亂,雖然品質還是很不令人滿意,不過重點是影響編輯模型可以如何與 GPT-4V 協作的過程,實際的應用品質,我相信等雙方都日漸成熟,這樣的工作模式一定也會是影像工作模式上的大躍進。
在本篇微軟的GPT-4V評測報告中,我們對GPT-4V在影像管理和生成方面的應用進行了深入的探討和實際的測試。透過個性化描述和精細的圖像分割技術,GPT-4V展示了其在相簿管理上的高效能力,使其能夠為照片提供個性化且具場景感知能力的描述。同時,我們也探討了影像生成應用,包括目標影像與提示詞的相似度評分,以及結合文字的相似度評分,發現GPT-4V在這些任務上也表現出色,可以透過語言模型和影像分析能力來提升影像生成的準確度和質量。
在實際測試中,GPT-4V能夠根據提供的人物設定資訊,辨識並描述照片中的特定人物和場景,即使在描述中存在一些小錯誤,其整體的識別和描述能力仍然令人印象深刻。在影像生成方面,GPT-4V在配合圖像編輯模型(如instruct pix2pix)時,能有效地提供改善建議,進一步優化了影像轉換的結果。
總結來說,GPT-4V的這些特性對於從事影像處理的專業人士來說非常有價值,能夠提升工作效率並擴展創造力。無論是在個性化的相簿管理、精細描述的創造,還是在與影像生成模型的協作應用上,GPT-4V均展示了強大的應用潛力和多樣化的實用性。
如果您喜歡我們這樣的內容,很歡迎到這裏訂閱我們的電子報,我們接下來的內容會在這裏優先發佈: ChatGPT 落地研究 | Ted (substack.com)

